乵僾僠楢嵹偱偡乶
俴倕倗倎們倷俉侽俉侽梡僆僾僔儑儞儃乕僪偺惢嶌
乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣
噴媄弍彮擭弌斉條偐傜俴倕倗倎們倷俉侽俉侽梡偺僆僾僔儑儞儃乕僪惢嶌偺埶棅傪庴偗傑偟偨丅
偦偺儃乕僪偵偼揹棳惂尷慺巕乮億儕僗僀僢僠乯傪偮偗傞偙偲偵側傝傑偟偨丅
偦偙偱乧丅
乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣
乵戞俀俁夞乶
仠俷倀俿柦椷丄俬俶娭悢偺僥僗僩乮俀乯
慜夞偐傜偺懕偒偱偡丅
慜夞偼嵟傕娙扨側俷倀俿柦椷偺僾儘僌儔儉偲丄偦偺撪梕傪堦晹曄峏偡傞偙偲偱彮偟偱偡偑幚峴帪娫傪抁弅偱偒傞僾儘僌儔儉傪徯夘偟傑偟偨丅
偝偰丄師偺僾儘僌儔儉偼慜夞曄峏偟偨僾儘僌儔儉偵偝傜偵彮偟曄峏傪壛偊偨僾儘僌儔儉偱偡丅
偙偺僾儘僌儔儉偺幚峴寢壥偼偳偆偱偟傚偆偐丠
10 'out test3
20 OUT $E3,$80
30 A%=0,B%=1,C%=$E0
40 OUT C%,A%:OUT C%,B%
50 GOTO 40
|
係侽峴偺俷倀俿暥偑儅儖僠僗僥乕僩儊儞僩偵側偭偰偄傑偡丅
壓偑幚峴寢壥偱偡丅
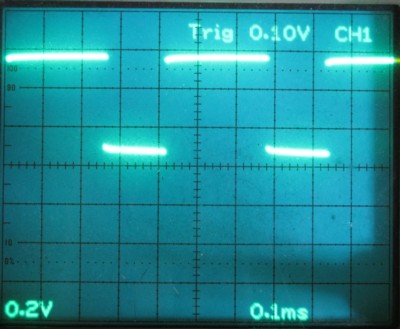
慜夞偺曄峏屻偺僾儘僌儔儉偼丄侾夞偺俫俴偺弌椡偵偐偐傞帪娫偑侽丏係係倣倱傎偳偵抁弅偝傟傑偟偨丅
偦傟偑崱夞偼偝傜偵傢偢偐偱偡偑侽丏係俀倣倱傎偳偵抁弅偝傟傑偟偨丅
侾峴偢偮幚峴偡傞偲偒偵丄師偺峴偵堏傞夁掱偱偄傠偄傠側嶌嬈傪峴側偭偰偄偰丄偦偺偨傔偵傢偢偐偱偡偑帪娫偑偐偐偭偰偟傑偄傑偡丅
儅儖僠僗僥乕僩儊儞僩偺応崌偵偼侾峴偺拞偱偡偖師偺柦椷傪撉傒崬傓憖嶌偵偐偐傞偨傔梋寁側帪娫偼偐偐傝傑偣傫丅
偦傟偑慜夞偺僾儘僌儔儉偲崱夞偲偺傢偢偐側幚峴帪娫偺嵎偵側傝傑偡丅
師偵俬俶娭悢偵偮偄偰傕僥僗僩傪偟偰傒傑偟偨丅
崱搙偼彮偟暋嶨側僥僗僩偱偡丅
壓偼僥僗僩拞偺幨恀偱偡丅

俛億乕僩偺價僢僩侽傪俙億乕僩偺價僢僩侽偵愙懕偟偰偄傑偡丅
壓偼僥僗僩僾儘僌儔儉偱偡丅
10 'out in test
20 OUT $E3,$82
30 OUT $E0,0
40 B%=IN($E1)
50 OUT $E2,B%
60 OUT $E0,1
70 B%=IN($E1)
80 OUT $E2,B%
90 GOTO 30
|
俀侽峴偱俛億乕僩偺傒傪擖椡偵愝掕偟傑偡丅
慜夞偺僥僗僩偲摨偠傛偆偵俙億乕僩偐傜侽丄侾傪弌椡偟傑偡偑丄崱搙偼弌椡偟偨捈屻偵俛億乕僩偺抣傪俬俶娭悢偱撉傒崬傒丄偦傟傪俠億乕僩偐傜弌椡偟傑偡丅
弌椡攇宍偺幨恀偱偡丅
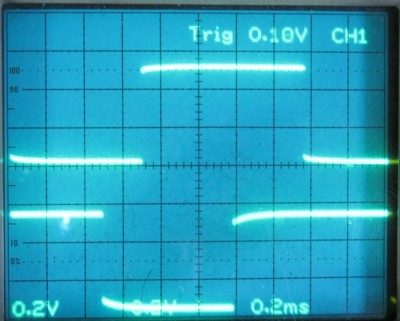
忋懁乮俠俫侾乯偑俙億乕僩偐傜偺弌椡偱丄壓懁乮俠俫俀乯偑俠億乕僩偐傜偺弌椡偱偡丅
忋偺幨恀偼丄俁侽峴偺俷倀俿丂亹俤侽丆侽偑幚峴偝傟偰俠俫侾偑俴偵側偭偨偁偲丄係侽峴偺俬俶娭悢偑幚峴偝傟丄偦偺偁偲俆侽峴偱俷倀俿丂亹俤俀丆俛亾偑幚峴偝傟偰俠俫俀偑俴偵側偭偨偙偲傪帵偟偰偄傑偡丅
俠俫侾偑俴偵側偭偰偐傜俠俫俀偑俴偵側傞傑偱偺帪娫偼栺侽丏俆倣倱偱偡丅
慜夞偺嵟弶偺僥僗僩偱俷倀俿柦椷偺幚峴帪娫偼侽丏俀倣倱偱偟偨丅
偲偄偆偙偲偼俬俶娭悢偺幚峴帪娫偼侽丏俁倣倱偲偄偆偙偲偵側傝傑偡丅
俠俫俀偑俴偵側偭偨偁偲俠俫侾偑俫偵側傞偺偵侽丏俀倣倱偐偐偭偰偄傑偡丅
偙傟偼俇侽峴偺俷倀俿暥偺幚峴寢壥偱偡丅
偦偺偁偲俠俫俀偑俫偵側傞傑偱偵侽丏俆倣倱偐偐偭偰偄傑偡丅
偙傟偼俈侽峴偲俉侽峴偺幚峴寢壥偱偡丅
偦偺偁偲俠俫侾偑俴偵側傞傑偱侽丏係倣倱傎偳偐偐偭偰偄傑偡丅
偙偙偼偪傚偭偲拲堄偑昁梫側偲偙傠偱偡丅
俋侽峴偺俧俷俿俷暥偲俁侽峴偺俷倀俿暥偺幚峴寢壥偱偡偐傜慜夞偺嵟弶偺僥僗僩偺寢壥偐傜峫偊傞偲偙偙偼侽丏俁倣倱偺偼偢側偺偱偡偑丅
幚偼偙偺僾儘僌儔儉偱偼俧俷俿俷暥偺幚峴帪娫偼侽丏俀倣倱偩偲峫偊傜傟傑偡丅
俧俷俿俷暥偼尰嵼偺儊儌儕忋偺埵抲偐傜慜偵丄傑偨偼屻傠偵弴偵峴斣崋傪僒乕僠偟偰偄偔傛偆偵嶌傜傟偰偄傑偡丅
俋侽峴偺俧俷俿俷暥偺峴偒愭偼俁侽峴偱偡偐傜尰嵼埵抲傛傝傕慜偵僒乕僠偟偰偄偒傑偡丅
慜夞偺嵟弶偺僾儘僌儔儉偺俧俷俿俷暥偼俆侽峴偵偁傝傑偟偨丅
娫偵偼係侽峴偺侾峴偑偁傞偩偗偱偡丅
崱夞偼娫偵係侽丄俆侽丄俇侽丄俈侽丄俉侽偲俆峴偺僾儘僌儔儉偑偁傝傑偡丅
偦偺峴斣崋傪俉侽峴偐傜媡偵僒乕僠偟偰偄偭偰俁侽峴偵峴偒拝偔傑偱偵偼慜夞偺僾儘僌儔儉傛傝傕懡偔偺帪娫傪昁梫偲偟傑偡丅
偦偺偨傔崱夞偺俧俷俿俷暥傪幚峴偡傞偺偵偼侽丏俀倣倱偐偐傞偲偄偆寢壥偵側偭偨偺偱偡丅
側偤俛俙俽俬俠僀儞僞僾儕僞偼偦傫側岠棪偺埆偄丄柺搢側巇慻傒偵側偭偰偄傞偺偐偲偄偄傑偡偲丄偦傟偼僀儞僞僾儕僞偺摿挜偵娭傢偭偰偄傑偡丅
僐儞僷僀儔偼僜乕僗僾儘僌儔儉傪婡夿岅偵枅夞東栿偟側偗傟偽側傝傑偣傫丅
偲偄偆偙偲偼偨偲偊偽娫偵僾儘僌儔儉傪捛壛偟偨傝嶍彍偟偨傝曄峏偟偨傝偟偰傕丄偐側傜偢僐儞僷僀儖偲偄偆嶌嬈傪偟傑偡偐傜丄僜乕僗僾儘僌儔儉偺曄峏偵偮偄偰偼壗傕峫偊傞昁梫偼偁傝傑偣傫丅
偦傟偩偗傓偟傠僐儞僷僀儔偺傎偆偑僔儞僾儖側峔憿偵偱偒傞偲傕偄偊傑偡丅
偙傟偵懳偟偰僀儞僞僾儕僞偼僜乕僗僾儘僌儔儉偺忬懺偺傑傑偱乮幚偼峴擖椡帪偵偨偩偪偵拞娫尵岅偵東栿偟偰偄傞偺偱偡偑乯偡偖偵幚峴偑壜擻偱偡丅
傑偨傕偲偺僾儘僌儔儉偵怴偨側峴傪捛壛偟偨傝嶍彍偟偨傝偟偰傕丄傗偼傝偡偖偵幚峴偱偒傑偡丅
傑偨慜夞尒偰偄偨偩偄偨傛偆偵丄儊儌儕偺拞偱偼拞娫僾儘僌儔儉偲偱傕偄偆傛偆側峔憿偵側偭偰偄傞偺偱偡偑丄偦傟傪乛俽俙倁俤僐儅儞僪偱僼傽僀儖偲偟偰僙乕僽偡傞偲丄拞娫僐乕僪偐傜晛捠偺僥僉僗僩暥傪惗惉偟偰僥僉僗僩僼傽僀儖偲偟偰曐懚偱偒傑偡丅
偦傟傜偺婡擻傪傕偨偣傞偨傔偵丄僀儞僞僾儕僞偼暋嶨側峔憿偑昁梫偵側傞偺偱偡丅
傕偪傠傫岺晇偵傛偭偰傕偭偲懍偔幚峴偱偒傞傛偆側峔憿偵偡傞偙偲傕偱偒傑偡偑丄偦偆偡傞偨傔偵偼俛俙俽俬俠僀儞僞僾儕僞杮懱偺僾儘僌儔儉僒僀僘偑傛傝戝偒側傕偺偵側偭偰偟傑偄傑偡偟丄偦偺奐敪偵偼傛傝懡偔偺帪娫傪昁梫偲偟傑偡丅
寛偟偰尰嵼偺婡擻偵枮懌偟偰偄傞傢偗偱偼偁傝傑偣傫偑丄僾儘僌儔儉偺夵椙偼側偐側偐戝曄側偙偲側偺偱丄偲傝偁偊偢偼尰嵼偺巇條偲側偭偰偄傑偡丅
側偍慜夞偲崱夞尒偰偄偨偩偄偨倅俛俁俛俙俽俬俠偺俷倀俿柦椷丄俬俶娭悢偺幚峴帪娫偼噴媄弍彮擭弌斉偺俴倕倗倎們倷俉侽俉侽偱偺幚峴寢壥偱偡丅
俶俢俉侽倅俁丏俆乮俶俢俉侽倅嘨乯偺倅俛俁俛俙俽俬俠偱傕摨偠僾儘僌儔儉偱僥僗僩偱偒傑偡偑乮偨偩偟偦偺応崌偵偼俬乛俷傾僪儗僗傪俤侽乣俤俁偐傜俉侽乣俉俁偵曄峏偡傞昁梫偑偁傝傑偡乯丄俴倕倗倎們倷俉侽俉侽偺俠俹倀僋儘僢僋偑侾侽俵俫倸偱偁傞偺偵懳偟偰俶俢俉侽倅俁丏俆乮俶俢俉侽倅嘨乯偼俇俵俫倸側偺偱丄偙偙偱愢柧偟偨幚峴帪娫傛傝傕抶偔側傝傑偡丅
偲偄偆偙偲偱倅俛俁俛俙俽俬俠偺俷倀俿柦椷偲俬俶娭悢偺幚峴帪娫偵偮偄偰尒偰偄偨偩偒傑偟偨偑丄嵟屻偵嶲峫傑偱偵摨偠偙偲傪儅僔儞岅僾儘僌儔儉偱幚峴偟偰傒傑偡丅
慜夞偺嵟弶偺僾儘僌儔儉偲慡偔摨偠摦嶌傪偡傞儅僔儞岅僾儘僌儔儉傪懄惾偱傾僪儗僗俋侽侽侽乣偵彂偄偰偡偖偵幚峴偟傑偟偨丅
偙偺傛偆偵抁偄僾儘僌儔儉偼儅僔儞岅僐乕僪傪偦偺傑傑俠俵僐儅儞僪偱彂偒崬傓偺偑堦斣庤偭庢傝憗偄曽朄偱偡丅
偙偙偱彂偒崬傫偩僾儘僌儔儉傪傾僙儞僽儔偺僾儘僌儔儉儕僗僩偲偟偰昞婰偡傞偲壓偺傛偆偵側傝傑偡丅
9000 3e80 LD A,80
9002 d3e3 OUT (E3),A
9004 3e00 LOOP:LD A,00
9006 d3e0 OUT (E0),A
9008 3e01 LD A,01
900A d3e0 OUT (E0),A
900C c30490 JP LOOP
|
幚峴寢壥偱偡丅
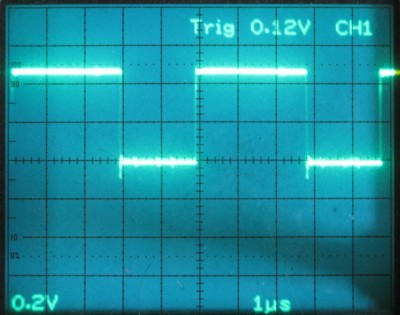
俫弌椡偑俁兪倱丄俴弌椡偼俀兪倱偱偡丅
偙偺偙偲偐傜俴俢偲俷倀俿偺幚峴帪娫偺崌寁偼俀兪倱丄俰俹偼侾兪倱偱偁傞偙偲偑暘偐傝傑偡丅
儅僔儞岅僾儘僌儔儉偼俛俙俽俬俠僀儞僞僾儕僞偺侾侽侽攞崅懍偱偁傞偲偄偆偙偲偑偄偊傞偱偟傚偆丅
慜夞丄崱夞偲楢嵹傪墑挿偟傑偟偨偑丄崱夞偱摉僾僠楢嵹偼廔椆偱偡丅
俴倕倗倎們倷俉侽俉侽梡僆僾僔儑儞儃乕僪偺惢嶌乵戞俀俁夞乶
俀侽侾俇丏俉丏俀侾倳倫倢倧倎倓
慜傊
儂乕儉儁乕僕僩僢僾傊栠傞