俹俬俠俛俙俽俬俠僐儞僷僀儔
乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣
傑傞偱僀儞僞僾儕僞丅偱傕僐儞僷僀儔偱偡丅挻僇儞僞儞挻僔儞僾儖偱偡丅
乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣
乵戞俇俉夞乶
仠俫俤倃僼傽僀儖斾妑僨乕僞偺専徹
慜夞偐傜偺懕偒偱偡丅
俹俬俠丂倂俼俬俿俤俼帋嶌俀崋婡偱俹俬俠侾俉俥侾俁俲俆侽偵彂偒崬傫偩僨乕僞乮僾儘僌儔儉乯傪廐寧偺俹俬俠僾儘僌儔儅偱撉傒弌偟偰嶌惉偟偨俫俤倃僼傽僀儖傪傕偲偺俫俤倃僼傽僀儖偲倂倝値俵倕倰倗倕偱斾妑偟偨偲偙傠堎側偭偰偄傞偲偙傠偑偁傝傑偟偨丅
崱夞偼偦偺堎側偭偰偄傞偲偙傠偺専徹偱偡丅
壓偼偦偺嵟弶偺晹暘偱偡丅
嵟弶偵偙偺晹暘傪尒偨偲偒偼乽側傫偠傖偙傝傖偁乿偲巚偭偨偺偱偡偑丄棊偪拝偄偰傛偔傛偔尒偨偲偙傠嵍塃偺僨乕僞偼摨偠偱偁傞偙偲偑傢偐傝傑偟偨丅
偦偺偙偲偵偮偄偰愢柧偡傞慜偵僀儞僥儖僿僉僒僼傽僀儖偺儗僐乕僪僼僅乕儅僢僩偵偮偄偰偺愢柧偑昁梫偱偡丅
奺儗僐乕僪偼丗乮僐儘儞乯偱巒傑傝傑偡丅
偦偺師偐傜悢抣偑懕偒傑偡偑偦偺悢抣偼侾僶僀僩偺侾俇恑悢傪俙俽俠俬俬俀暥帤偱昞偟偨傕偺偱偡丅
丗偵懕偔侾僶僀僩偺悢乮俙俽俠俬俬俀寘乯偼偦偺儗僐乕僪偺僨乕僞悢傪僶僀僩悢偱帵偟偰偄傑偡丅
偦偺師偺俀僶僀僩乮俙俽俠俬俬係寘乯偼傾僪儗僗傪帵偟傑偡乮偙傟偼僨乕僞僶僀僩悢偵偼娷傑傟傑偣傫乯丅
偦偺師偺侾僶僀僩乮俙俽俠俬俬俀寘乯偼偦偺儗僐乕僪偺懏惈傪帵偟傑偡丅
儗僐乕僪偺懏惈偑侽侽偺偲偒偦偺儗僐乕僪偼捠忢偺傾僪儗僗偲僨乕僞傪娷傒傑偡丅
嵍懁偺俀峴栚傪偦偺儖乕儖偵廬偭偰撉傫偱傒傑偡丅
侽係偼僶僀僩悢偱偡丅
師偺侽侽侽侽偼傾僪儗僗偑侽侽侽侽偱偁傞偙偲傪帵偟傑偡丅
師偺侽侽偼捠忢偺儗僐乕僪偱偁傞偙偲傪帵偟偰偄傑偡丅
偦偺師偐傜偺係僶僀僩乮俙俽俠俬俬俉寘乯偑僨乕僞偱偡丅
侽俠俤俥侽侽俥侽偱偡丅
嵟屻偺侾侾偼偙偺儗僐乕僪偺僠僃僢僋僒儉偱偡丅
偙偺儗僐乕僪偼傾僪儗僗侽侽侽侽乣侽侽侽俁偺僨乕僞偑侽俠俤俥侽侽俥侽偱偁傞偙偲傪帵偟偰偄傑偡丅
崱搙偼塃懁傪尒偰傒傑偡丅
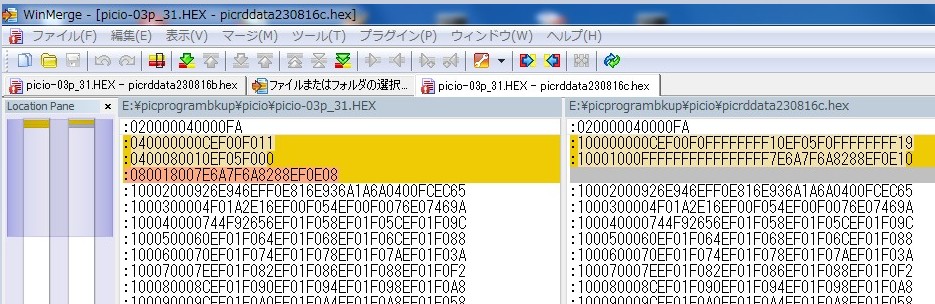
嵟弶偺侾侽偼偙偺儗僐乕僪偵娷傑傟傞僨乕僞偑侾俇僶僀僩乮侾侽俫乯偱偁傞偙偲傪帵偟偰偄傑偡丅
師偺侽侽侽侽偼傾僪儗僗偱偡丅
偦偺師偺侽侽偼捠忢偺儗僐乕僪偱偁傞偙偲傪帵偟偰偄傑偡丅
偦偺師偐傜偑僨乕僞偱偡丅
侽俠俤俥侽侽俥侽偲偙偙傑偱係僶僀僩偼嵍懁偲堦抳偟偰偄傑偡丅
偦偺師偐傜偺偲偙傠偼堦扷抲偔偙偲偵偟偰嵍懁偺俁斣栚偺儗僐乕僪傪尒偰傒傑偡丅
傾僪儗僗侽侽侽俉乣侽侽侽俛偺係僶僀僩偺僨乕僞偑侾侽俤俥侽俆俥侽偱偁傞偙偲傪帵偟偰偄傑偡丅
嵍懁偱偼傾僪儗僗侽侽侽係乣侽侽侽俈偑偁傝傑偣傫丅
偙偺娫偵偼僨乕僞偑柍偄偙偲傪帵偟偰偄傑偡丅
偝偰偦偙偱塃懁偵栠傝傑偡丅
塃懁偱偼傾僪儗僗侽侽侽係乣侽侽侽俈偵憡摉偡傞偲偙傠偺抣偼俥俥俥俥俥俥俥俥偵側偭偰偄傑偡丅
僼儔僢僔儏儊儌儕偱壗傕彂偒崬傑傟偰偄側偄偲偙傠偼俥俥偱偡丅
偦偟偰偦偺師偵偼係僶僀僩偺僨乕僞侾侽俤俥侽俆俥侽偑偁偭偰偙偙偼嵍懁偲摨偠偱偡丅
偦偺師偺傾僪儗僗侽侽侽俠乣侽侽侽俥偼傑偨俥俥俥俥俥俥俥俥偵側偭偰偄傑偡丅
塃懁偺師偺俁儗僐乕僪栚傕僨乕僞悢偼侾俇僶僀僩偵側偭偰偄偰傾僪儗僗偼侽侽侾侽偐傜偵側偭偰偄傑偡丅
僨乕僞偼俥俥偑俉屄懕偄偰偄傑偡偐傜傾僪儗僗侽侽侾侽乣侽侽侾俈偼僨乕僞偑俥俥偱偁傞偙偲傪帵偟偰偄傑偡丅
偦偺師偺俈俤俇俙俈俥俇俙俉俀俉俉俤俥侽俤偼傾僪儗僗侽侽侾俉乣侽侽侾俥偺僨乕僞偱偡丅
偙傟偼嵍懁偺係斣栚偺儗僐乕僪偺撪梕偲堦抳偟傑偡丅
嵍懁偱偼傾僪儗僗侽侽侽俠乣侽侽侾俈偑敳偗偰偟傑偡丅
偦偺娫偼僨乕僞偑柍偄偙偲傪帵偟偰偄傑偡丅
偙偺傛偆偵斾妑偟偰傒傞偲俀偮偺俫俤倃僼傽僀儖偺偙偺晹暘偼儗僐乕僪偺昞帵偐傜尒傞偲堦尒堎側偭偰偄傞傛偆偱偡偑幚偼摨偠偱偁傞偙偲偑傢偐傝傑偡丅
摨偠撪梕偺偼偢側偺偵側偤偙偺傛偆側堘偄偑弌偰偔傞偺偱偟傚偆偐丅
偦傟偼嵍懁偺俫俤倃僼傽僀儖偑俵俹俴俙俛偺俹俬俠傾僙儞僽儔偵傛偭偰僜乕僗僼傽僀儖傪傕偲偵偟偰嶌惉偝傟偨僼傽僀儖偱偁傞偺偵懳偟偰塃懁偺俫俤倃僼傽僀儖偼俹俬俠侾俁俲俆侽偵彂偒崬傑傟偨侾俇恑僐乕僪傪撉傒弌偟偰嶌惉偝傟偨俫俤倃僼傽僀儖偩偐傜偱偡丅
嬶懱揑偵愢柧偟傑偡丅
偙偆偄偆偙偲偱偡丅
壓偼傕偲偵側偭偨俫俤倃僼傽僀儖偺傾僙儞僽儖儕僗僩偱偡丅