標準TTLだけ(!)でCPUをつくろう!(組立てキットです!)
(ホントは74HC、CMOSなんだけど…)
[第535回]
●デバッグ作業の続き、のつもりだったのですが…
前回、「おばかなことをやっておりました」と書きました。
突然ブレイクもしない、ハングアップもしないで終了してしまう、という肩透かしの状態になってしまったものですから、ついうろたえてしまいました。
なんだかテストプログラムが蒸発してしまったような、異な感じになりまして…。
dmコマンドでメモリの中身を確認してみたら、ちゃんとあるじゃないのお。
なのに、なぜか全く実行してくれないで、でもハングアップもブレイクもしないで、しれっとして終了してしまうって、どういうこと?
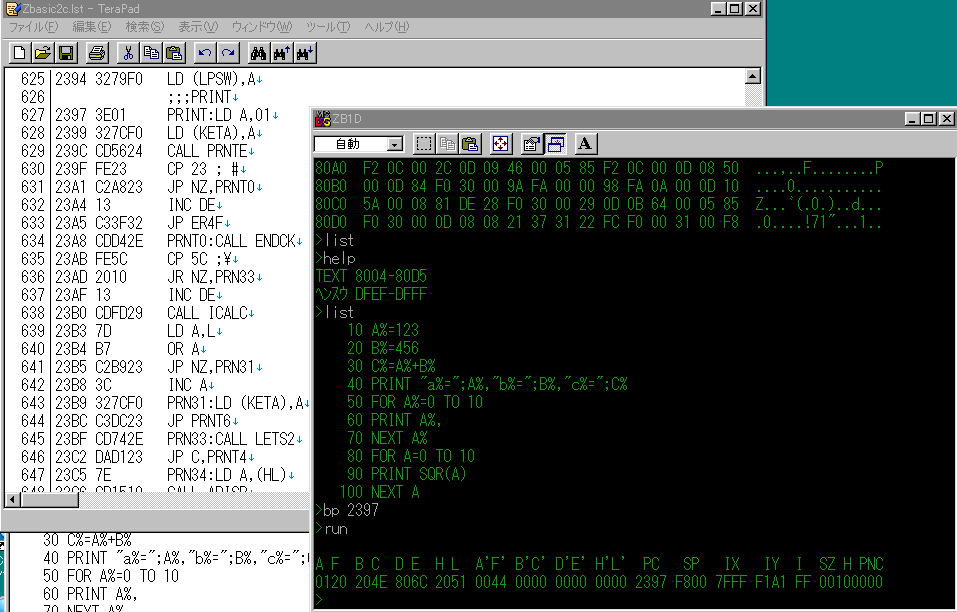
listコマンドを入力してみたけれど、何も表示されません。
う。リストが表示されない?
……!
わかりましたあ。
そりゃあ、当たり前でした。
前回、ハングアップしてしまったときに、一旦強制終了して、それからあらためてZ80BASICシステムを起動したのでありました。
その直後にブレイクポイントを設定して、runしたのですから、何も実行しないのが当たり前でした。
Z80BASICの起動直後は、ユーザープログラムは見かけ上はクリアされているのでありました。
自分でそのように設計しておいて、自分で忘れてしまうのですからたまりません(トホ…)。
いやあ。じつに、なんともおはずかしい。
helpコマンドを実行してから、listコマンドを実行しました。
今度はちゃんとテストプログラムが表示されました。
あらためて、2397にブレイクポイントを設定してrunしました。
おお。
今度はちゃんとアドレス2397でブレイクしました。
PRINTルーチンの入り口には来ているようです。
これから先はちょいとしたテクニックなのですが、命令を1つずつ順にブレイクさせながら実行していくのでは手間がかかってたまりません。
JP命令などのプログラムが分岐するポイントごとにブレイクさせるようにすると、効率よいデバッグが行えます。
2397でPRINTルーチンにエントリした後の最初の分岐は23A1のJP NZ命令です。
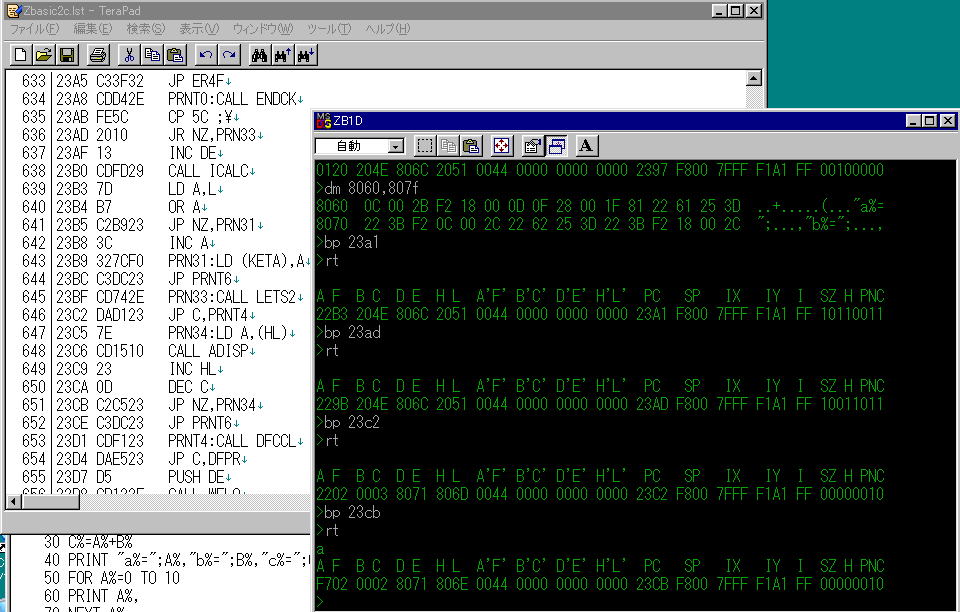
そこで、23a1にブレイクポイントを設定するのですが、画面を見ますと、その前に
dm 8060,807f
を実行しています。
実はメモリのこのあたりに、これから実行するPRINT命令があるので、そこを確認しているのです。
●BASICプログラムの構造について
BASICのプログラム(ユーザープログラム)は、list文で表示されるままの形でメモリに入れられるのではなくて、処理効率がよくなるように中間コードに変換してからメモリに入れられます。
ただPRINT文の” ”で囲んだテキストのように、そのままの文字列を表示するような命令では、その文字列部分はそのままの形でメモリに入れられます。
dmコマンドで表示された内容を、右のASCIIダンプ部分で確認してみますと、行番号40のPRINT文にある、”a%=”や”b%=”がそのままあることがわかります。
しかし、その前のあたりを見ても、どこにもPRINTの文字はありません。
実はPRINTという命令は、プログラムを入力した時点で、81というコードに変換される仕組みになっているのです。
上の画面のメモリダンプリストを見ますと、アドレス806Bに81があります。
ことのついでですから、Z80BASICのデータ(ユーザプログラム)の構造について簡単に説明をいたしましょう。
ちょうど、今ターゲットにしております、PRINT文について説明をすることにいたします。
今回のテストプログラムのプログラムリストと、メモリダンプリストは、前回の作業画面に見えますけれど、そのところだけ、ログファイルから切り取って、下に示します。
>help
TEXT 8004-80D5
ヘンスウ DFEF-DFFF
>list
10 A%=123
20 B%=456
30 C%=A%+B%
40 PRINT "a%=";A%,"b%=";B%,"c%=";C%
50 FOR A%=0 TO 10
60 PRINT A%,
70 NEXT A%
80 FOR A=0 TO 10
90 PRINT SQR(A)
100 NEXT A
>dm 8000,80d5
8000 41 55 54 4F 00 80 FF DF 10 80 0C 00 B3 53 44 94 AUTO...゚....ウSD.
8010 40 F4 41 25 00 00 00 85 0A 00 02 00 42 F4 42 25 @.A%........B.B%
8020 00 00 00 85 14 00 02 00 44 F4 43 25 00 00 00 85 ........D.C%....
8030 1E 00 02 00 F0 DF 41 00 00 00 00 85 50 00 04 00 .....゚A.....P...
8040 0A 00 08 F2 0C 00 9A FA 7B 00 0D 0B 14 00 08 F2 ........{.......
8050 18 00 9A FA C8 01 0D 0B 1E 00 0C F2 24 00 9A F2 ....ネ.......$...
8060 0C 00 2B F2 18 00 0D 0F 28 00 1F 81 22 61 25 3D ..+.....(..."a%=
8070 22 3B F2 0C 00 2C 22 62 25 3D 22 3B F2 18 00 2C ";...,"b%=";...,
8080 22 63 25 3D 22 3B F2 24 00 0D 22 32 00 0D 84 F2 "c%=";.$.."2....
8090 0C 00 9A FA 00 00 98 FA 0A 00 0D 10 3C 00 06 81 ............<...
80A0 F2 0C 00 2C 0D 09 46 00 05 85 F2 0C 00 0D 08 50 ...,..F........P
80B0 00 0D 84 F0 30 00 9A FA 00 00 98 FA 0A 00 0D 10 ....0...........
80C0 5A 00 08 81 DE 28 F0 30 00 29 0D 0B 64 00 05 85 Z...゙(.0.)..d...
80D0 F0 30 00 0D 08 08 21 37 31 22 FC F0 00 31 00 F8 .0....!71"...1..
helpコマンドを実行すると、リセットによって見かけ上クリアされていたユーザープログラムが復活するとともに、ユーザープログラムが格納されているメモリ範囲が表示されます。
プログラムエリアを確認するために、helpコマンドを繰り返し実行することができます。
8004−80D5と表示されています。
この範囲に、LISTコマンドで表示されるプログラムが中間コードに変換されて納められています。
LISTコマンドは、この中間コードから、もとのソースプログラムリストを逆生成して表示させているのです。
Z80BASICはインタプリタです。コンパイラではありません。
たとえばCコンパイラのように、ソースプログラムからマシン語コードに変換する形式では、コンパイラによって生成されたマシン語プログラムから、もとのソースプログラムを逆生成することは、なにかの仕掛けが埋め込まれていない限り不可能です。
インタプリタは逐次翻訳型と言われるように、実行の都度翻訳しながら進みます。
その分実行速度は遅くなりますが、コンパイル作業が不要で、プログラムの作成作業中にいつでも実行させることができ、また個々のBASICの命令をコマンドの形でダイレクトに実行することもできます。
ソースプログラムをそのままメモリに保存しておいて、実行時に文字比較を行って命令を検出するようにすれば、システムプログラムの構造は簡単になりますし、LISTコマンドもシンプルになります。
しかし、実行のたびに、たとえば’P’’R’’I’’N’’T’という文字データを順番に比較していって、PRINT命令に行きつく、という作業を繰り返しおこなうのは余りに無駄ですし、実行時間のほとんどが毎回の翻訳作業のために使われてしまって極めて非能率です。
そこで一般的なBASICインタプリタは、最初のプログラムの入力時に、可能な限り中間コード形式に翻訳してしまって、実行時の負担を少なくするようにしています。
あ。
ここで説明をしております、Z80BASICの構造は、私が独自に工夫したものですから、たとえばNECのN88BASICなどとは、BASICの構造や中間コードレベルでの互換性は全くありません。
さてそこで、行番号40のPRINT文です。
ダンプリストの右のASCIIダンプ部分を見ていただきますと、そこに
”a%=”;
,”b%=”;
,”c%=”;
がみつかります。
この部分はプログラムリストのそのままの形になっています。
メモリダンプの右の部分には何の意味があるのだろう、と疑問だったかもしれませんが、こういう目的には実にピッタリなのです。
ダンプリストの”a%=が表示されている行を左に見ていきますと、その各文字の16進数コード22 61 25 3Dがあります。
その左(アドレス806B)にある81がPRINT命令のコードです。
そのさらに左の3バイトを見ますと、
28 00 1Fになっています。
ここが行の先頭です。
行番号40の行の先頭アドレスは、8068です。
最初の2バイトは、行番号を下位、上位の順に並べたものです。
行番号40は16進数に直すと0028です。
行番号は2バイト16ビットですから、行番号としては0001〜7FFF、つまり1〜32767が許されることになります。
その次の1Fは、この行のここから後ろのバイト数です。
Z80BASICインタプリタは、1行を画面表示の2行以上の長さにすることはできません。
1行の長さの最大値は80字ですから、16進数の50が最大値です。
実際にはソース文は通常は中間コードに翻訳される過程で圧縮されて短くなりますから、行の長さ情報の最大値は50よりもさらに小さくなります。
いずれにしても、ここは1バイトで足ります。
なぜ、ここに行の長さの情報を置いているか、といいますと、それは行の挿入や削除の作業を効率良くおこなえるようにするためです。
BASICなどの言語プログラムを自作してみよう、と思ってみえる方も多いと思いますが、実際にはなかなか大変な作業が必要なのです。
BASICの個々の命令の実行部分を作ることもさることながら、さきほど説明をしました、ソースコード←→中間コードの翻訳プログラムを作ることもなかなかにしんどい作業になりますし、ソースプログラムの一部を書き換えたり(当然1行の長さが変わります)、行を挿入したり、削除したりすることにも対応しなければなりません。
一朝一夕にはできない、という言葉がありますが、まさにその言葉通りで、このZ80BASICも長い時間を費やして作り上げてきたものです。
ええ。私ひとりだけで。
なにしろ一匹狼が身上で、協調性ゼロなものですから。
つい余談になりました。
さきほどの行の長さ情報の1Fを、そのアドレス(806A)に加算します。
806A+1F=8089です。
メモリダンプリストの8089を見ますと、0Dになっています。
ここが行の終わりです。
行の終わりには複改(CR)コード0Dを置きます。
実は本当の行の終わりはそのもう1バイト次にあります。
アドレス808Aです。
22になっています。
これも行の長さ情報です。
行の終わりの位置からみて、行の先頭のアドレスを算出するための情報です。
22をそのアドレス(808A)から減算します。
808A−22=8068です。
さきほどの行番号40の行の先頭アドレスに一致しました。
このデータも、行の挿入、削除のための情報に使われます。
さてでは次に、さきほどのPRINT文の文字定数部分、
”a%=”;
,”b%=”;
,”c%=”;
のそれぞれの後ろに注目してみます。
説明が長くなりましたから、その部分だけもう一度切り取って下に示します。
8060 0C 00 2B F2 18 00 0D 0F 28 00 1F 81 22 61 25 3D ..+.....(..."a%=
8070 22 3B F2 0C 00 2C 22 62 25 3D 22 3B F2 18 00 2C ";...,"b%=";...,
8080 22 63 25 3D 22 3B F2 24 00 0D 22 32 00 0D 84 F2 "c%=";.$.."2....
それぞれの後ろには、
F2 0C 00
F2 18 00
F2 24 00
が置かれています。
これが変数の中間コードなのです。
最初のF2は、この変数が整数型であることを示しています。
その次の2バイトは、変数の情報を格納しているアドレスを示しています。
000C、0018、0024です。
プログラムの先頭アドレス8004にそれぞれを加算してみます。
8004+000C=8010
8004+0018=801C
8004+0024=8028
になります。
あ。この部分ももう一度切り取って下に示すことに致しましょう。
8000 41 55 54 4F 00 80 FF DF 10 80 0C 00 B3 53 44 94 AUTO...゚....ウSD.
8010 40 F4 41 25 00 00 00 85 0A 00 02 00 42 F4 42 25 @.A%........B.B%
8020 00 00 00 85 14 00 02 00 44 F4 43 25 00 00 00 85 ........D.C%....
8030 1E 00 02 00 F0 DF 41 00 00 00 00 85 50 00 04 00 .....゚A.....P...
8010には
40 F4 41 25 …
というデータがあります。
最初の2バイトは、この変数の値が置かれているアドレスを示しています。
F440です。
前回、前々回で、変数A%は固定アドレスF440に置かれています、というように説明しました。そのアドレス情報がここに置かれています。
その次からの5バイトは変数名のエリアです。
Z80BASICでは変数名は5文字までしか扱えません。
ちょっと窮屈ですが、限られたメモリサイズの中で、できるだけたくさんの変数を扱えるようにしたい、と考えたためです。
ここには、41 25が置かれています。
変数名A%の文字コードです。
このエリアには、そのほかの情報が置かれています。
名前情報の1バイト置いて次には
0A 00 02
があります。
最初の2バイトは、この変数が最初に書かれた行番号を示しています。
000Aですから行番号10です。
次の02は、この変数のデータがもっている長さの情報です。
A%は整数型の変数ですから、そのデータ長は16ビット、つまり2バイトです。
B%、C%についても同じルールで置かれていることがおわかりいただけると思います。
今回はPRINT命令のデバッグ作業について説明するつもりだったのですが、BASICプログラムの構造についての説明がずいぶん長くなってしまいましたので、デバッグ作業につきましては、次回、ということにさせていただきます。
2010.6.27upload
前へ
次へ
ホームページトップへ戻る