侾俇價僢僩儅僀僐儞儃乕僪偺惢嶌
乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣
偄偮偐巊偭偰傒傞偮傕傝偱擖庤偟偰偦偺傑傑抲偄偰偁偭偨侾俇價僢僩俠俹倀偺偙偲傪巚偄弌偟傑偟偨丅
俙俵俢幮偺俙俵侾俉俉偱偡丅
偦偺柤偺捠傝丄俠俹倀僐傾偼俉侽侾俉俉屳姺偺侾俇價僢僩俠俹倀偱偡丅
偦偺俙俵侾俉俉傪巊偭偨侾俇價僢僩儅僀僐儞儃乕僪偺惢嶌婰帠偱偡丅
乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣乣
乵戞俆係夞乶
仠俙俵侾俉俉俤俵偺俠俴俷俠俲乮係乯
慜夞偐傜偺懕偒偱偡丅
僇儊儗僆儞儘僕傾僫偼乽俿俿俴偱俠俹倀傪偮偔傠偆乿乵戞俁俈係夞乶偱徯夘偄偨偟傑偟偨丅
側偐側偐偵曋棙側桪傟傕偺偱偡丅
塃壓偵尒偊傞偺偑僇儊儗僆儞儘僕傾僫偱偡丅

慜夞傑偱偺僥僗僩偱丄偳偆傕俙俵侾俉俉偺柦椷偲僋儘僢僋偺娫偵側偵傗傜晄揔愗側娭學偑偁傝偦偆側媈偄偑擹岤偵側偭偰偒傑偟偨丅
偦偙偱僇儊儗僆儞儘僕傾僫偱僠僃僢僋偟堈偄傛偆偵丄偆傫偲僔儞僾儖側僾儘僌儔儉傪幚峴偝偣偰傒傞偙偲偵偟傑偟偨丅
壓偑偦偺儕僗僩偱偡丅
2018/7/11 7:226 86cktst8.LST
[00001] ;;; clock test for am188
[00002] ;
[00003] ORG=8000
[00004] ;
[00005] 8000 FEC0 LOOP:INC AL;3
[00006] 8002 EBFC90 JMP LOOP;14 <8000>
[00007] ;
[00008] ;END
LOOP =8000
|
傕偆偙傟埲忋娙扨側僾儘僌儔儉偼柍偄丄偲偄偆偔傜偄僔儞僾儖側僾儘僌儔儉偱偡丅
側偍俰俵俹丂俴俷俷俹偺儅僔儞岅僐乕僪偼
俤俛俥俠俋侽
偵側偭偰偄傑偡偑丄偙傟偼帺嶌俉侽俉俇傾僙儞僽儔偺庤敳偒偱丄
俰俵俹丂俴俷俷俹偺儅僔儞岅僐乕僪偼
俤俛俥俠
偱偡丅
偦偺偆偟傠偺俋侽偼俶俷俹偱偡丅
傾僙儞僽儔偺搒崌偱偙偆偄偆儅僔儞岅偵側傝傑偡偑丄幚梡忋栤戣偼偁傝傑偣傫丅
偙偺僾儘僌儔儉傪幚峴偟偰丄偦傟傪僇儊儗僆儞儘僕傾僫偱娤應偟傑偟偨丅
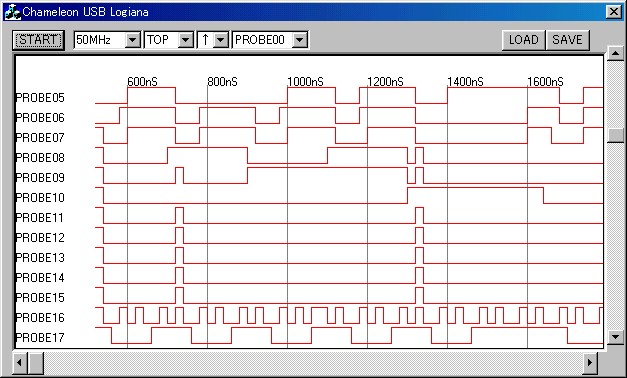
夋柺偱偼堦晹偑塀傟偰偄傑偡偑俹俼俷俛俤侽侽乣侽俈偑僨乕僞僶僗俢侽乣俢俈丄俹俼俷俛俤侽俉乣侾俆偑傾僪儗僗僶僗俙侽乣俙俈偱偡丅
俹俼俷俛俤侾俇偑俠俴俲俷倀俿俙乮侾侽俵俫倸僋儘僢僋乯丄俹俼俷俛俤侾俈偼俼俙俵俼俢偱偡丅
偪傚偆偳俇侽侽値倱偺嬤曈偱傾僪儗僗俉侽侽侽偺撉傒崬傒偑峴側傢傟偰偄傑偡丅
偦偺偁偲俉侽侽値倱乮俉侽侽侾乯丄侾侽侽侽値倱乮俉侽侽俀乯丄侾俀侽侽値倱乮俉侽侽俁乯丄侾係侽侽値倱乮俉侽侽係乯偲俼俙俵偐傜偺撉傒崬傒偑峴側傢傟丄彮偟娫偑嬻偄偰侾俈侽侽値倱嬤曈偱嵞傃俉侽侽侽偺撉傒崬傒偵栠偭偰偄傑偡丅
堦弰偡傞偺偵侾侾侽侽値倱偐偐偭偰偄傑偡丅
偲偙傠偱偙偺儖乕僾偼忋偺儕僗僩偵婰嵹偟偨僋儘僢僋悢偱寁嶼偡傞偲侾俈僋儘僢僋偱偡偐傜丄侾俈亊侽丏侽俆亖侽丏俉俆兪倱乮俉俆侽値倱乯偺偼偢偱偡丅
偍偐偟偄偠傖偁傝傑偣傫偐丅
俀俆侽値倱傕僆乕僶乕偟偰偄傑偡丅
偳偙偐偑偍偐偟偄丠
丠丠丠丠丠
両
偁偭両
偦偆偄偆偙偲偐両
側傫偰偙偭偨偄丅
偙偺壗擔娫傕偺娫丄婱廳側帪娫傪旓傗偟偰丄偦傟偑偙傫側偙偲偩偭偨偲偼丅
偆偆傓丅
側傫偲嬸偐側偙偲傪丅
傕偭偲憗偔婥偑晅偔傋偒偱偁傝傑偟偨丅
傗偭傁傝倅俉侽傗俉侽俉侽偺摢偱偮偄峫偊偰偟傑偭偰偄傑偟偨丅
俉侽俉俇偼侾俇價僢僩偱偁傞埲忋偵丄俉侽俉侽傗倅俉侽偲偼偦偺傾乕僉僥僋僠儍偑慡偔堎側偭偰偄偨偺偱偟偨丅
倅俉侽傗俉侽俉侽偼柦椷傪儊儌儕偐傜撉傒崬傫偱偦傟傪夝撉偟幚峴偟丄偦偟偰傑偨師偺柦椷傪儊儌儕偐傜撉傒崬傫偱丄偲偄偆棳傟偱張棟傪恑傔傑偡丅
摉慠柦椷偵偐偐傞幚峴帪娫偼儊儌儕偐傜撉傒崬傓帪娫偲偦傟傪夝撉偟偰幚峴偡傞帪娫偺崌寁偱偡丅
偲偙傠偑俉侽俉俇偼乮摉慠俙俵侾俉俉傕乯偦偙偺偲偙傠偑慡偔堎側偭偰偄偨偺偱偟偨丅
俉侽俉俇偼柦椷傪儊儌儕偐傜撉傒崬傓晹暘偲丄柦椷傪夝撉偟偰幚峴偡傞晹暘傪暘棧偟偰撈棫偝偣傑偟偨丅
儊儌儕偐傜撉傒崬傓婡峔偼丄柦椷偺幚峴偲偼娭學側偔乮幚嵺偼柍娭學偵偼偱偒側偄偺偱偡偑乯儊儌儕偐傜柦椷傪傾僪儗僗弴偵撉傒崬傫偱僶僢僼傽偵拁偊偰偄偒傑偡丅
偦傟傪幚峴偡傞婡峔偼僶僢僼傽偐傜弴師柦椷傪撉傒弌偟偰夝撉偟幚峴偟偰偄偒傑偡丅
俙俵侾俉俉偺僨乕僞僔乕僩偵偁偭偨柦椷偺幚峴僋儘僢僋悢偼丄偙偺撪晹揑偵夝撉偟幚峴偡傞偺偵偐偐傞僋儘僢僋悢偱丄偦傟偲乽柍娭學偵乿暲峴偟偰峴側傢傟傞儊儌儕偐傜偺撉傒崬傒帪娫偼丄柦椷偺幚峴僋儘僢僋悢偵偼娷傑傟偰偄側偐偭偨偺偱偟偨丅
偦傟偱媈栤偑夝偗傑偟偨丅
俙俵侾俉俉偑儊儌儕偐傜僐乕僪傪撉傒庢傞偺偵偼係僋儘僢僋偐偐傝傑偡丅
慜夞偺儊儌儕俼俤俙俢偺倂倎倴倕倖倧倰倣傪嶲徠偟偰偔偩偝偄丅
偲偙傠偑忋偺儕僗僩偵偁傝傑偡傛偆偵俬俶俠丂俙俴偺僋儘僢僋悢偼俁僋儘僢僋偱偡丅
儊儌儕偐傜侾僶僀僩傪撉傓偺偵係僋儘僢僋偐偐傞偺偵丄幚峴帪娫偑俁僋儘僢僋偲偄偆偺偼偍偐偟偄偠傖偁傝傑偣傫偐丅
偦傟偼儊儌儕偐傜撉傒崬傓偺偵偐偐傞帪娫傪彍奜偟偨撪晹偩偗偺幚峴僋儘僢僋悢偩偭偨偺偱偟偨丅
偦偆偄偆偙偲偩偭偨偺偱偡丅
壖偵僗僞乕僩偟偨捈屻偱僶僢僼傽偵偼壗傕傑偩撉傒崬傑傟偰偄側偄偲偡傞偲丄俠俹倀偼寢嬊僶僢僼傽偵柦椷偑撉傒崬傑傟傞傑偱懸偭偰偄傞偟偐偁傝傑偣傫丅
偦偟偰係僋儘僢僋屻偵傗偭偲俬俶俠丂俙俴偑撉傒崬傑傟偰丄偦傟傪俠俹倀偑俁僋儘僢僋偱幚峴偟偰偟傑偭偨偲偟偰傕丄傑偨僶僢僼傽偼嬻偱偡偐傜丄傗偭傁傝傕偆侾僋儘僢僋偼懸偮偟偐偁傝傑偣傫丅
偦偙偵寁嶼傛傝傕梋寁偵偐偐傞僋儘僢僋悢偺懚嵼偑擣傔傜傟傑偡丅
偦偟偰俰俵俹柦椷偲偐俠俙俴俴柦椷偵偼傕偆傂偲偮崲擄側栤戣偑偁傝傑偡丅
偦傟偑忋偺儘僕傾僫偺僠儍乕僩偵昞傢傟偰偄傑偡丅
俉價僢僩偺奣擮偱儊儌儕偐傜撉傒崬傑傟傞偲偒偺傾僪儗僗傪捛愓偡傞偲丄壓偺傛偆偵側傝傑偡丅
俉侽侽侽仺俉侽侽侾仺俉侽侽俀仺俉侽侽俁仺俉侽侽侽
偲偙傠偑忋偺儘僕傾僫偺僠儍乕僩偱偼
俉侽侽侽仺俉侽侽侾仺俉侽侽俀仺俉侽侽俁仺俉侽侽係仺俉侽侽侽
偺傛偆偵側偭偰偄傑偟偨丅
俙俵侾俉俉俠俹倀偺撪晹偺幚峴偺條巕偼尒傞偙偲偼偱偒傑偣傫丅
儘僕傾僫偺僠儍乕僩偐傜傢偐傞偺偼丄儊儌儕偐傜撉傒崬傓婡峔偺撉傒崬傒摦嶌偩偗偱偡丅
傾僪儗僗俉侽侽係偼杮棃偼撉傒崬傓昁梫偼側偄傕偺側偺偱偡偑丄儊儌儕偐傜偺撉傒崬傒偼柦椷偺夝撉幚峴偲偼堦墳柍娭學偵峴側傢傟傞偺偱丄撉傒崬傑傟偰偟傑偄傑偡丅
偦偺捈屻偵俰俵俹柦椷偑夝撉幚峴偝傟丄偦偙偱俉侽侽侽斣抧偺柦椷傪撉傔丄偲偄偆僐儅儞僪偑撪晹揑偵弌偝傟偰丄偡傞偲撉傒崬傑傟偰偄偨僶僢僼傽偺撪梕偼偦偙偱攋婞偝傟偰丄怴偨偵俉侽侽侽偐傜撉傒捈偡偲偄偆摦嶌偑峴側傢傟傑偡丅
偍偦傜偔偙偺娫偺儘僗僞僀儉偑忋偺寁嶼偱弌偰偒偨丄梋暘偵偐偐偭偨俀俆侽値倱乮俆僋儘僢僋乯偩偭偨偲峫偊傜傟傑偡丅
偙偺傛偆側棳傟偺曄峏偵傛傞僶僢僼傽偺僋儕傾偍傛傃暿偺傾僪儗僗偐傜偺嵞撉傒崬傒偼俰俵俹柦椷偩偗偱偼側偔偰丄俰俶倅側偳偺忦審僕儍儞僾柦椷傗俠俙俴丄俼俤俿偱傕敪惗偡傞偼偢偱偡丅
傑偨棳傟偼曄傢傝傑偣傫偑丄儊儌儕傊偺僨乕僞偺彂偒弌偟傗丄俬俶丄俷倀俿柦椷偺幚峴偺娫丄儊儌儕偐傜偺楢懕撉傒崬傒偼堦帪拞抐偝傟傑偡丅
偙偙傑偱彂偄偰偒偰丄撍慠偱偡偑丄傕偆傂偲偮媈栤偵巚偭偰偒偨偙偲偺堄枴偑傢偐傝傑偟偨丅
僨乕僞僔乕僩偵婰嵹偝傟偰偄傞柦椷偺幚峴僋儘僢僋偑俉侽俉俇偲俉侽俉俉偱摨偠偵側偭偰偄傞柦椷偑懡偔偁傞偺偼側偤偐丄偲偄偆媈栤偱偡丅
俉侽俉俇偺僨乕僞僶僗暆偼侾俇價僢僩偱偡偐傜儊儌儕偐傜堦搙偵俀僶僀僩傪撉傒崬傒傑偡丅
俉侽俉俉偺僨乕僞僶僗暆偼俉價僢僩偱偡偐傜堦搙偵侾僶僀僩偟偐撉傔傑偣傫丅
偦傟側傜偦偺暘偩偗俉侽俉俉偼俉侽俉俇傛傝傕幚峴僋儘僢僋悢偑梋寁偵偐偐傞偼偢偱偼側偄偐丠
偲偄偆媈栤偩偭偨偺偱偡偑丄偍偦傜偔俉侽俉俇偲俉侽俉俉偺俠俹倀僐傾偼摨偠偼偢偱丄偩偐傜撪晹偺柦椷夝撉幚峴僋儘僢僋悢偼俉侽俉俇偲俉侽俉俉偱摨偠偱偁偭偰傕壗偺晄巚媍傕側偐偭偨偺偱偟偨丅
摉慠儊儌儕偐傜柦椷僨乕僞傪撉傒崬傓偺偵偐偐傞帪娫偼丄俉侽俉俉偼俉侽俉俇偺攞傪梫偟傑偡丅
柦椷偺幚峴僋儘僢僋悢偵娭學側偔俉侽俉俉偼俉侽俉俇傛傝傕幚峴帪娫偼抶偔側傞偼偢偱偡丅
偝偰偦偆偄偆偙偲偵側傞偲丅
偦傕偦傕偙偲偺敪抂偱偁傝傑偟偨丄俢俽侾俁侽俈偲偺捠怣偺偨傔偵昁梫側俆兪倱偺僂僃僀僩僞僀儅乕偼嶌傟側偄偠傖側偄偐丄偲偄偆偍榖偵側傝傑偡丅
偦偺捠傝偱偡丅
俉侽俉侽傗倅俉侽側傜偽僋儕僗僞儖敪怳偺惛搙偵崌偆掱搙偺惓妋偝偱僜僼僩僂僃傾偵傛傞抶墑僞僀儅乕傪幚尰偡傞偙偲偑偱偒傑偡丅
偟偐偟俉侽俉俇偱偼丄崱傑偱愢柧偟偰偒傑偟偨棟桼偐傜丄偍偦傜偔偦偺傛偆側惓妋側僜僼僩僂僃傾僞僀儅乕傪嶌傞偙偲偼偱偒傑偣傫丅
俆兪倱偑俈兪倱偵側偭偰偟傑偆掱搙偺傾僶僂僩偝偼擣梕偡傞偟偐偁傝傑偣傫偱偟傚偆丅
侾俇價僢僩俠俹倀偑偦傫側偄偄壛尭側偙偲偱傛偄偺偐丠
慠傝丅
偦偙偼俉價僢僩偺摢傪侾俇價僢僩懳墳偵愗傝姺偊傞傋偒偱偁傝傑偟傚偆丅
偍偦傜偔侾俇價僢僩偺悽奅偱偼惓妋側僞僀儅乕偼奜晹儁儕僼僃儔儖偵媮傔傞傋偒丄偲偄偆偺偑忢幆側偺偱偼偁傝傑偡傑偄偐丅
侾俇價僢僩儅僀僐儞儃乕僪偺惢嶌乵戞俆係夞乶
俀侽侾俉丏俈丏侾俀倳倫倢倧倎倓
慜傊
師傊
儂乕儉儁乕僕僩僢僾傊栠傞